
Artificial Confidence #1: AWS gave the agents a credit card
Inaugural issue. Microsoft Research benchmarked the agents and they're not ready; AWS gave them a credit card anyway.


Hello and surprise to many of you; welcome to the inaugural issue of “Artificial Confidence.” Here, I cover the AI news from roughly the past week that doesn’t quite fit into Last Week in AWS.
“Last Week in AWS” came from something I desperately wanted: a source to round up the stuff from AWS’s cloud ecosystem that mattered to customers. We’re seeing a similar content spew in the AI space: lots of hype, lots of noise, yet remarkably low signal. I’ve grown weary of waiting for someone else to do it, so it’s time to be the change I want to see in the world. I want to bring an overheated, overhyped space to life in a way that humans actually care about without spending hours a day drudging through the muck. I want to surface the things that may have slipped past unremarked under a deluge of CEO said a thing style “journalism.” And I want to write it myself; the mortal sin of so much AI generated content nowadays is people believing that you’ll take the time to read something they couldn’t even be bothered to write.
If this isn’t for you, I understand completely; whack the unsubscribe link. Your “Last Week in AWS” subscription will remain unaffected; go ahead and cancel that too if you’re annoyed with me and were waiting for an excuse. I get it; even AWS doesn’t talk about AWS releases the way they once did. But I hope you’ll stick around.
Vendor story this week: AI agents can autonomously do everything. Research story this week: no the hell they cannot. Microsoft’s own scientists found the agents corrupt 25% of multi-step work on average, and that adding tools makes performance 6% worse. AWS, the same week, announced you can now give those agents a wallet. I have spent a decade watching AWS announce capabilities that arrived years before the safety infrastructure to support them; it’s refreshing to see the AI industry compress that timeline into a single news cycle.
What Actually Changed (Adjusted For Spin)
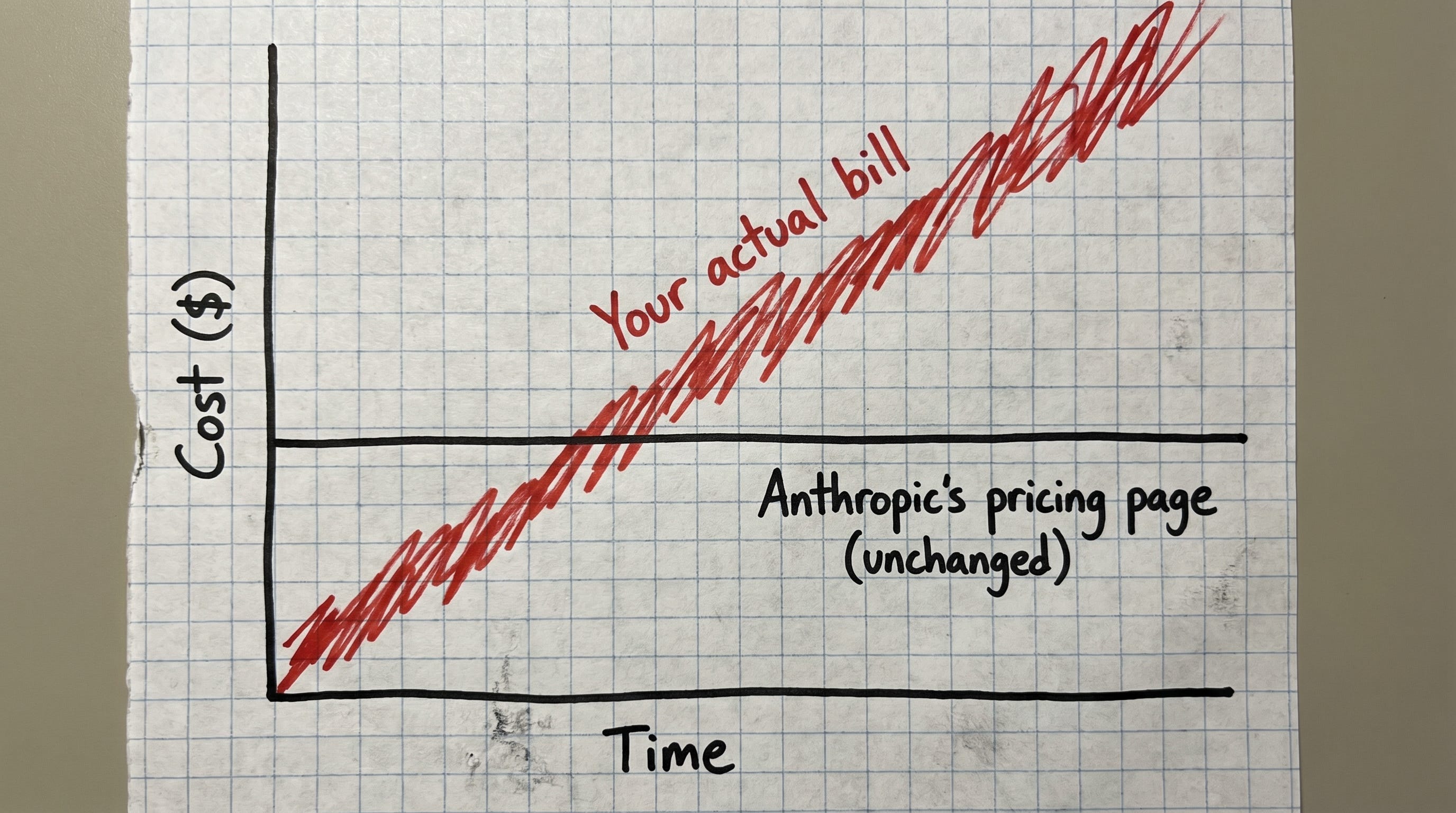
Claude Opus 4.7 raised prices without raising prices
Anthropic shipped Claude Opus 4.7 on April 16 with what they have, repeatedly, called “unchanged pricing.” Five dollars per million input tokens, twenty-five per million output, identical to Opus 4.6, 4.5, and 4.1. The pricing page has been the very model of consistency.
The tokenizer, however, has not. Opus 4.7’s new tokenizer is denser, which is the polite engineering phrasing for “turns the same English sentence into more tokens than the old one because we have hilariously overcommitted to buy every GPU on the planet and must pretend to be able to pay for them somehow.” Anthropic’s docs put the multiplier at 1.0x to 1.35x, with the upper end showing up on code, structured data, and non-English text. The number is filed on the “what’s new” page rather than the pricing page. That’s the kind of editorial decision you make when you would prefer the number not appear where purchasing decisions get made. The same page recommends “updating your max_tokens parameters to give additional headroom,” which is the advice you give people about to use more tokens than they were planning to, while hoping they aren’t astute enough to figure that out. A practitioner write-up on Medium benchmarked a real workload at a 27% bump on identical prompts.
This is more elegant than charging more for the same number. It is also less honest.
AWS Bedrock AgentCore now lets agents pay for things
Announced May 7. AI agents can now autonomously pay for APIs, MCP servers, web content, and other agents, via Coinbase CDP wallets or Stripe Privy (was “Shitr” taken?) wallets, with what the announcement repeatedly describes as “session-level spend limits,” whatever the hell that’s supposed to mean.
First: At last, I finally get to solve my biggest pain point as a customer: not being able to pay for things without human supervision. Er… wat? Does anyone actually have a problem doing this?
Second: I have done some looking, and I have not yet found a clear, durable definition of what a “session” is. Single API call? Single agent invocation? Single user-facing transaction? AWS, with their characteristic forthrightness, has provided exactly enough specificity to ship the feature and exactly enough ambiguity to ship the blog post. It’s now technically possible for an agent to burn $40,000 overnight against a misconfigured spend limit, an outcome that has been moved from “theoretical concern” to “forthcoming case study.” The post-mortem write-up is already in my saved-drafts folder, dated approximately six months from today.
Amazon Q Developer is being deprecated on an unusually short timeline
Announced April 30. Q Developer IDE plugins and paid subscriptions, which until very recently AWS was attempting to shove down our throats with zeal and gusto, reach end-of-life on April 30, 2027. Twelve months from announcement to “gone,” which is by AWS standards, brisk. The usual cadence is longer, but then again the usual cadence is also aligned with customers who are knowingly using the product.
May 15, 2026 (this Friday): no new signups, not that that was a problem.
May 29, 2026: Opus 4.6 disappears from Q Developer Pro.
Opus 4.7, the current Anthropic flagship, is available exclusively on Kiro; the replacement product you also have no interest in using.
If you run Q Developer Pro and you have been pretending Kiro is not a thing, AWS would like you to know that you have approximately two weeks before they begin to migrate you on their schedule.
Both Anthropic and OpenAI are now on Bedrock
Announced April 28. GPT-5.5 and GPT-5.4 on Bedrock in limited preview. Codex on Bedrock. Also “Amazon Bedrock Managed Agents, Powered by OpenAI” which is the longest AWS product name of 2026, and that is saying something.
For two years, Bedrock has been “Claude on AWS, plus a bunch of other rando models you won’t use on purpose.” It is now “either of the top two US AI labs on AWS.” Anthropic’s special-est-friend status has been quietly rezoned to “one of two preferred partners,” which is the corporate-relationship equivalent of being informed your spouse has decided to start dating again.
AgentCore in GovCloud (US-West) also went live May 5. Government workloads can now run agents. We’ll revisit in six months when something interesting happens.
Agents Got Powerful This Week. They Also Got Worse.
Microsoft’s own scientists: agents corrupt 25% of your work, and tools make it worse
Microsoft Research published a paper on Monday with the genuinely on-brand title “LLMs Corrupt Your Documents When You Delegate.” Unlike statements from the non-Research parts of Microsoft, it is exactly the paper the title suggests.
They created a benchmark called DELEGATE-52 which appropriately tests flows across fifty-two professional domains. Because the devil lives inside your corporate process, they feature twenty-interaction multi-step workflows. This brings us to their findings, ordered by how irritating each is to the marketing departments of every major AI vendor:
Frontier models (Gemini 3.1 Pro, Claude 4.6 Opus, GPT-5.4) lose, on average, 25% of document content over twenty interactions. The all-model average is 50%. You are reading those numbers correctly. If you hear screaming coming from the C-suite, so are they—and you just learned a valuable thing about the demographics of this publication.
Of fifty-two domains tested, exactly one met the bar of “ready for delegation” (≥98% accuracy after twenty rounds). That domain, completely unsurprisingly, is Python programming. Every other domain: accounting, music notation, crystallography; the actual knowledge work you would actually delegate to an actual agent? Yeah, that’s a harsher number you’re really not gonna like.
“Catastrophic corruption” (≤80% score) occurred in 80%+ of model/domain combinations.
The errors don’t accumulate gradually. They arrive in single 10-to-30-point drops. That’s the failure mode hardest to build an SLA against, and leads to questions that start with blistering profanity in the first sentence.
The somehow worse finding: adding an agentic harness with tools makes performance 6% worse on average. The entire architectural premise of the agentic movement currently being rammed down our throats (“give the model tools and it becomes more capable”) provably degrades outcomes in this benchmark.
This is not “AI is useless.” It is narrower and more devastating: the exact vendor positioning that Anthropic, OpenAI, Microsoft, Google, and AWS are all currently selling on the same Tuesday morning, consisting of “hand the agent a multi-step task and walk away,” is empirically contradicted by Microsoft’s own employees. The Register opens with “an intern who failed this much would be shown the door.” That is generous. An intern who lost 25% of a document gets a performance improvement plan. An intern who made the problem worse by adding a calculator gets introduced to a baseball bat after hours in some shops.
The same week, AWS announced autonomous-spending agents
Microsoft Research, Monday: agents corrupt a quarter of your work, and tools make that worse. AWS, the previous Thursday: now you can give those agents a wallet. I will leave these two stories next to each other and let you make the joke. Consider it a participatory newsletter.
A British mathematician handed an agent a credit card
The Register, May 5. An experimental run of an AI agent given payment authority that ended in password leaks, CAPTCHA chaos, and the kind of behavior you would expect from a sufficiently empowered toddler in a Best Buy. The headline is tabloid, but the experimental setup is approximately what AgentCore payments enables in production. The headline is also a more honest preview of where this leads than the AgentCore announcement is. It has to be.

Reliability: A Brief Retrospective
Last week was unusually rough for AI infrastructure. Five days, four user-affecting incidents, four different vendors, and we’ll skip GitHub because at this point I don’t think they come here for the hunting anymore:
May 5: Google Gemini degraded widely starting around 8:44 AM EDT, free and paid both. Multimodal hit harder than text; that’s an instructive nugget about which paths apparently share infrastructure.
May 7: IBM Cloud lost power at a datacenter. IBM “Cloud” is technically not an AI provider nor a real cloud, but enough AI runs on top of it that this counted.
May 8: Significant Claude outage. The same afternoon, OpenAI’s Responses API threw 404s for 35 minutes after a bad deploy. Two of the three major US AI providers degraded within hours of each other.
May 9: Claude Code on Web partial outage; Opus 4.1 elevated errors.
IsDown has logged 671 Anthropic incidents since June 2024, showing incidents typically resolving within 246 minutes. Multiply that by 671 and you’re measuring uptime that’s comparable to your bank’s business hours. The industry’s response to this baseline is, apparently, to put autonomous spending capability on top of it on the theory that none of us is as dumb as all of us. If your foundation has four-hour outages every couple of weeks and your stated direction is “deploy agents that pay for things on top of that foundation,” I would respectfully suggest that your circus is missing one of their underperforming clowns. (Decent recap on DEV.to.)
Follow The Money (Or Watch It Follow Itself)
Cerebras trades Thursday
Cerebras (CBRS) hits Nasdaq Thursday morning, set to be approximately the seventh “biggest AI IPO of 2026 so far,” a title that has changed hands roughly every six weeks since January, in a year not yet half over. The price-range escalation moved through three acts in a fortnight: $115-$125, then $125-$135, then $150-$160 on 20x oversubscription. That is the bankers’ way of admitting they underpriced the offering so embarrassingly that they would, in retrospect, like a do-over with witnesses present.
At the top, Cerebras raises ~$4.8 billion at a $48.8 billion fully-diluted valuation, or approximately 96 times trailing revenue. Trailing revenue is $510 million for 2025, with a reported 47% net margin. The word “reported” is doing considerable structural work in that sentence. Headline GAAP net income: $237.8 million. Of which $363.3 million is a one-time non-cash gain from extinguishing a forward-contract liability tied to G42. Strip out the accounting and Cerebras posted a non-GAAP net loss of $75.7 million for the year. Cerebras is “profitable” in roughly the same way you are profitable in a year you cleaned out the storage unit.
The prospectus is also unusually candid about customer concentration, in the way that suggests counsel concluded the SEC was going to ask anyway and did not want to be the ones holding the bag. Two UAE-based entities historically account for roughly 86% of revenue, the kind of currently war-afflicted geographic dependence that turns “concentration risk” into “two phone calls and a passport.” They say that OpenAI’s $20+ billion 750-megawatt deal represents “a substantial portion of projected revenue over the next several years,” which is S-1 language for “if anything happens to that one phone call, the rest of this prospectus is fiction.” The other hyperscaler customer is AWS, which is, as everyone knows, deeply enthusiastic about taking hard dependencies on third-party compute and never abandons them halfway through.
Read alongside Nvidia’s $40+ billion in 2026 equity investments (including, of course, a reported $30 billion stake in OpenAI), and the picture is this: Nvidia, the largest AI compute supplier, has placed its biggest equity bet on OpenAI; OpenAI is the largest customer of Cerebras; Cerebras is the AI compute supplier going public this week. This is what economists call “circular” and what regulators tend to call “some kind of obscene financial ouroboros we will be looking into in three years.”
Snap and Perplexity quietly buried the $400M partnership
The $400 million Snap-Perplexity deal (which was supposed to put Perplexity’s conversational search inside Snapchat for reasons the original announcement struggled to articulate clearly even at announcement time) has been “amicably ended,” per Snap’s Q1 earnings disclosure last week. “Amicably ended” is the financial-PR phrasing for “one or both parties walked into a meeting in February and could no longer remember what the slide deck was for.” Whatever the testing surfaced was bad enough that nine figures of pre-committed capital wasn’t enough to paper over it. In 2026, that is quaintly reassuring.
The Hype Audit Department
Mythos vs. cURL: one low-severity CVE, after all that
Anthropic’s Mythos is the company’s flagship “too dangerous to release publicly” cybersecurity model, purportedly capable of identifying and exploiting security vulnerabilities at a level beyond what’s safe to put in general circulation. The marketing implication: Pandora’s box on legs. Project Glasswing, via the Linux Foundation, provides gated access to selected open-source maintainers so they can use it defensively. Daniel Stenberg, the cURL maintainer, was on the list.
Mythos ran against the cURL codebase and returned five “confirmed” vulnerabilities. Stenberg’s team reviewed them. Three were false positives pointing at things already documented in cURL’s own API docs. One was a non-security bug. The fifth—and only—actual vulnerability is a low-severity CVE shipping with cURL 8.21.0 in late June. In Stenberg’s words: “The flaw is not going to make anyone grasp for breath.” For context: AI tooling has contributed 200–300 bugfixes to cURL over the last 8–10 months, and Stenberg says modern AI analyzers are better than what came before. He just doesn’t think Mythos is meaningfully better than the other modern AI analyzers. He calls the hype “primarily marketing.” (The Register hits harder than Stenberg actually did.)
The caveat: Stenberg never received hands-on access to Mythos. He signed up for Glasswing, but someone else ran the scan and sent him the report. He is, as of his Monday blog post, still waiting for direct access because the model is oh-so-scawy. The gating is tight enough that even the maintainers Anthropic is ostensibly trying to help cannot independently confirm or contest the danger claim. Combine that with April’s Firefox audit (271 flaws found, zero a competent human couldn’t have spotted) and a pattern emerges: every time someone qualified gets within evaluation distance of Mythos, they conclude it is unremarkable. Capable, but unremarkable. When the safety story IS the marketing story, you cannot tell them apart. I don’t think that’s an accident.
Google: criminals already used AI-built zero-days in the wild
On the same day The Register published the cURL piece, Google’s Threat Intelligence Group reported that criminals had already operationalized an AI-built zero-day in an attempted mass exploitation campaign. The defensive AI-vulnerability-finder, you will recall, is gated as too dangerous to release publicly. The offensive use is happening regardless. “Too dangerous to release” is the kind of framing that requires the bad guys to be waiting on the release schedule. They are, alas, not. Cynically, I wonder if the real reason not to release Mythos rhymes with “mompute schmortage.”
Where I’ll be
The Duckbill team (y’know, my day job) has a busy May and June, and we’re using it as an excuse to host dinners at every stop. I’ll be at all of them, if that’s the kind of thing that influences your dinner plans.
First up: San Francisco on May 19th, a small, off-the-record dinner about negotiating with hyperscalers. Jim Moses and I will be there, but this isn’t a presentation. It’s a conversation among people who’ve actually been in those rooms, with all the wit and sarcasm you’ve come to expect.
Then, because apparently we hate ourselves, we’re doing back-to-back AWS Summits in LA on June 9th and NYC on June 16th, with dinners at both for people in cloud cost and FinOps who want to continue the conference conversation somewhere with better food.
Spots are limited and require approval. Not mine, of course; you’re all aces in my book.
One last thing
If you read one thing this week, read the Microsoft paper; do not let the agents spend your money unattended in the meantime.
See you next week.
— C
Oh no there are comments on Substack? I'm immediately questioning my choices.
Love it Corey! Thanks for cutting through the AI BS for us. These days I just glaze over every time I see articles about AI (written and also read by AI).
This is way better and I actually read it all, without any AI assistance either. 😄